The importance of high availability

Inova 2021 exhibition show visit
November 10, 2021
Using DynConD as a traditional server-side GSLB
January 10, 2022Prompted by the recent events where Amazon Web Services went down for the second time in the span of a few weeks and social media giant Facebook suffering from ever-increasing downtimes in the last couple of months, it is important to highlight one of the most important aspects and features in modern and complex network systems – High Availability.
High Availability (HA) is often referred to as the ability of a network system to operate with no downtime or failing for a prolonged period of time. The term high availability is often mentioned alongside other popular terms like load balancing and instant failover and as such is a crucial topic for any DevOps or System administrator operating modern network infrastructure. In today’s competitive market, maximum productivity and reliability are extremely important for all organizations, and any system downtime or malfunction can lead to the loss of data, customer dissatisfaction, and financial loss. With an abundance of available options, the average consumer will simply divert their attention and money to the next best available option on the market. This is a big reason why most hosting and cloud providers advertise a 99,9999% uptime of their servers. However, sometimes even that is not enough and unpredictable natural hazards like fires, floods or earthquakes or calculated DDoS and cyber-attacks can occur and even the best equipped and set-up data centers will go down.
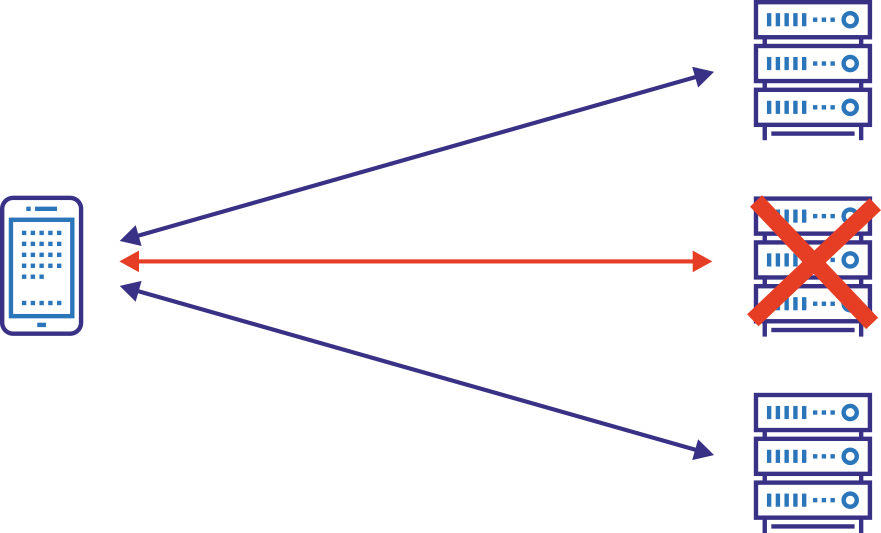
To ensure the high availability of an application or service, it’s best advised to have it hosted and running in different heterogeneous data centers spread across multiple geographic locations with multiple internet service providers attached.
Such a set-up can be costly, but it is also necessary to guarantee maximum uptime, reliability and potential for the application or service to scale out when needed. A sudden influx of users can very quickly lead to server congestion and reduced quality of the service and then being able to scale out becomes mandatory.
Another issue that needs to be addressed is that once the application or service is distributed in multiple data center locations, is how to ensure maximum performance for all users that are accessing it. A service or application that is running extremely slowly and feels unresponsive is almost as big of a problem as not having it run at all.
The distribution of thousands and sometimes even millions of user requests per second between data centers can be a real challenge and this is where load balancing comes in, more specifically, global server or cloud load balancing.
Legacy server-side GSLB’s usually use static load balancing algorithms such as random, round robin or weighted round-robin or occasionally a bit more sophisticated algorithms such as least connections or weighted least connections to distribute the load between data centers and servers.
Modern DNS based client-side GSLB’s and cloud load balancers however have the capability to measure the network distance between each user (client) and server, service response time and server load and calculate the composite DNS metric for each server to ensure that the client always connects to the optimal server for him. This method of server selection automatically provides health checks and instant failover because in an event that one data center (server) goes down, the client will automatically be routed to another, the next best one suited for him. Implementing such a system can be sometimes very costly, complicated and bothersome. Fortunately, we at DynConD have found a way to provide applications with the necessary Global Server Load Balancing and High Availability through a few easy-to-implement steps that require no advanced coding knowledge and can be done quickly for a fraction of the cost of other solutions. For more information, visit https://www.dyncond.com/dyncond-implementation/ and DynConD user portal https://my.dyncond.com/
